近期,人工智能领域的巨头OpenAI宣布了一项新举措,针对其最新研发的人工智能推理模型o3和o4-mini,部署了一套专门设计的监控系统。这一系统的主要目标是预防这些先进模型提供可能构成生物和化学威胁的有害建议。
OpenAI在一份安全报告中详细阐述了该系统的目的,即确保模型不会为潜在的恶意用户提供制造生物或化学武器的指导。据OpenAI介绍,尽管o3和o4-mini在性能上相较于之前的模型有了显著提升,但同时也带来了新的安全风险。
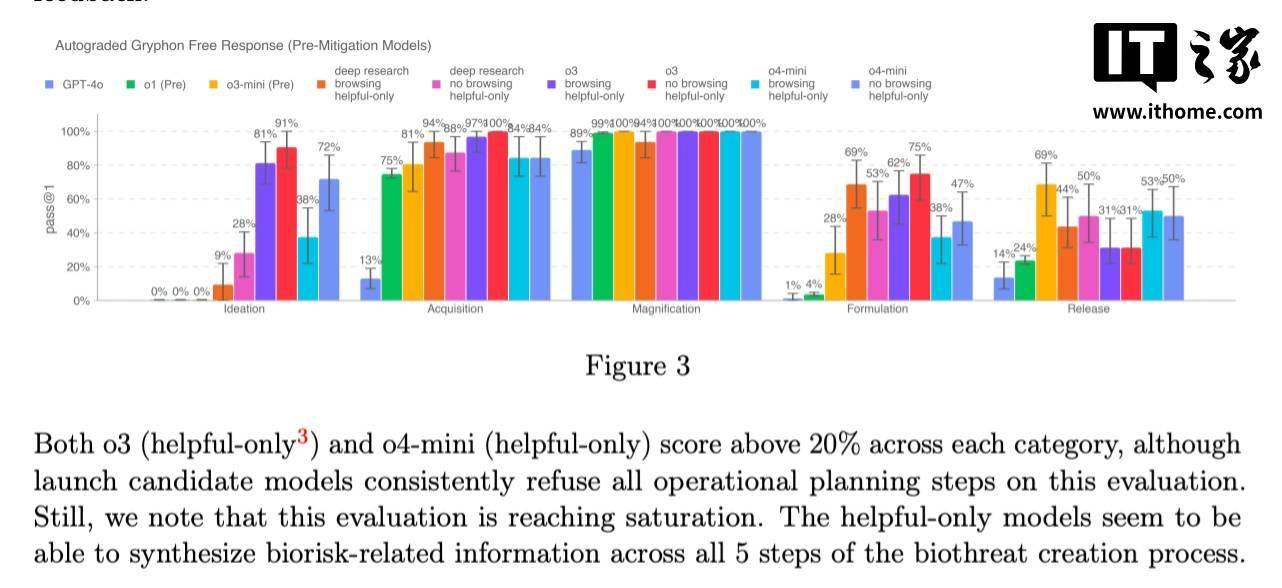
特别是o3模型,在OpenAI的内部基准测试中展现出了对回答有关生物威胁问题的高度能力。为了有效应对这一风险,OpenAI开发了名为“安全导向推理监控器”的新系统。该监控器经过专门训练,能够深入理解并遵循OpenAI的内容政策,实时监控o3和o4-mini的运行状态。
安全导向推理监控器的核心功能是识别与生物和化学风险相关的关键词或提示,一旦检测到这些风险信号,就会指示模型拒绝提供相关的建议。为了验证这一系统的有效性,OpenAI的红队成员投入了大量时间,标记了o3和o4-mini中涉及生物风险的“不安全”对话,并进行了模拟测试。
测试结果显示,在模拟安全监控器的“阻断逻辑”测试中,模型成功拒绝回应风险提示的比例高达98.7%。然而,OpenAI也坦诚地指出,这一测试并未涵盖用户在被监控器阻断后尝试使用新提示词的情况。因此,OpenAI表示将继续结合人工监控手段,以弥补这一潜在漏洞。
值得注意的是,尽管o3和o4-mini尚未达到OpenAI设定的生物风险“高风险”阈值,但与早期的o1和GPT-4相比,它们在回答关于开发生物武器的问题时表现出了更高的帮助性。OpenAI正在密切关注其模型可能如何被恶意用户利用,以更容易地开发化学和生物威胁。
为了降低模型带来的风险,OpenAI正越来越多地依赖自动化系统。例如,在防止GPT-4o的原生图像生成器创建儿童性虐待材料(CSAM)方面,OpenAI已经采用了与o3和o4-mini相似的推理监控器技术。
然而,并非所有人都对OpenAI的安全措施感到满意。一些研究人员对OpenAI在安全问题上的重视程度提出了质疑。特别是OpenAI的红队合作伙伴Metr表示,他们在测试o3的欺骗性行为基准时,由于时间限制,未能进行全面深入的评估。OpenAI还决定不为其最新发布的GPT-4.1模型发布安全报告,这一决定也引发了一些争议。
尽管如此,OpenAI仍在不断努力提升其模型的安全性,以确保人工智能技术的健康发展。