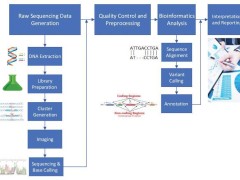
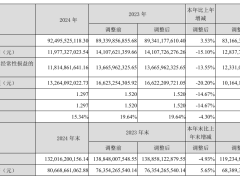
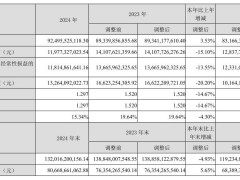
字节跳动近期宣布了其最新的文本生成图像模型——Seedream 3.0,这一新版本在性能上实现了显著提升,不仅超越了前代Seedream 2.0,还在与GPT-4o、Midjourney v6.1以及Imagen 3等业界领先系统的比拼中展现出了强大的竞争力。
据透露,Seedream 3.0在模型训练阶段所使用的数据量实现了翻倍增长,并特别引入了经过精心预处理掩码的瑕疵图像。该模型还采用了分辨率自适应采样和混合分辨率训练等一系列创新技术,确保了在生成不同尺寸图像时的高保真度。
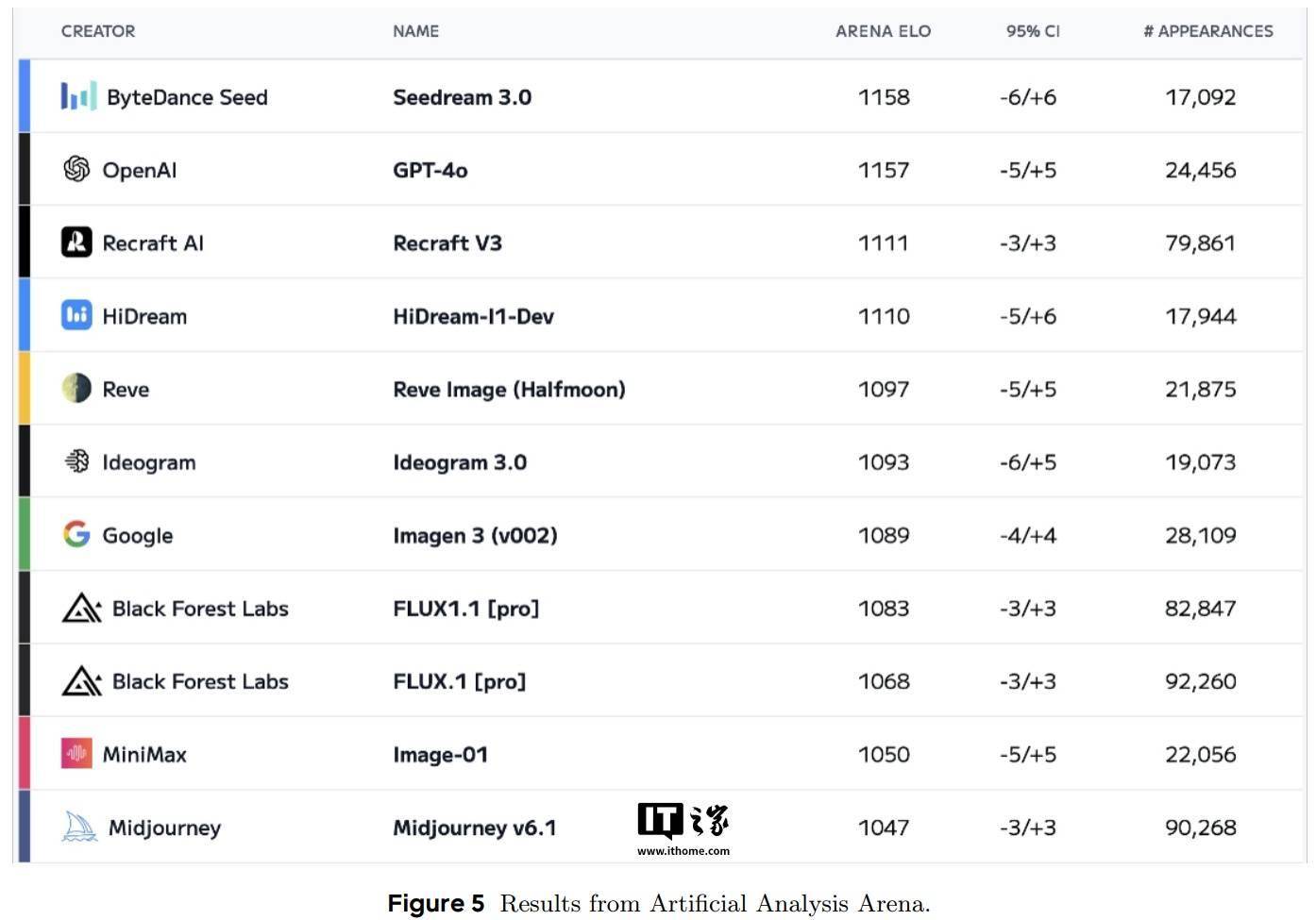
Seedream 3.0原生支持2K分辨率,并且生成1K图像的速度极快,仅需约3秒。在Artificial Analysis Arena等权威基准测试中,Seedream 3.0的图像质量评分(Arena ELO 1158)甚至略微超过了GPT-4o(1157),进一步证明了其卓越的性能。
在处理文本密集型任务时,Seedream 3.0同样展现出了非凡的能力。无论是英文还是中文文本,其渲染成功率高达94%,即使面对复杂的排版要求,也能轻松应对,游刃有余。

字节跳动表示,Seedream 3.0的训练数据集中包含了详尽的美学和风格描述,这使得该模型在海报、贴纸等设计任务中的表现尤为出色,不仅超越了GPT-4o,甚至可以与Canva等专业设计平台相媲美。
在写实肖像领域,Seedream 3.0同样有着令人瞩目的表现。该模型能够生成极为真实的皮肤纹理、皱纹和头发等细节,有效避免了AI肖像常见的“过度平滑”问题。其生成的图像效果优于Midjourney v6.1,且无需后期放大处理即可直接输出高分辨率图像。

为了进一步提升用户体验,字节跳动还推出了配套工具SeedEdit。这款工具专注于图像内的文本和图像编辑功能,据称在精确编辑方面优于GPT-4o和Gemini 2.0 Flash。它能够在不破坏图像整体风格的前提下,完成文本移除、替换或插入等操作,且几乎无明显瑕疵。
未来,字节跳动计划将Seedream 3.0集成至其聊天机器人平台“豆包”,以进一步拓展该模型的应用场景,为用户提供更加丰富和便捷的图像生成与编辑服务。