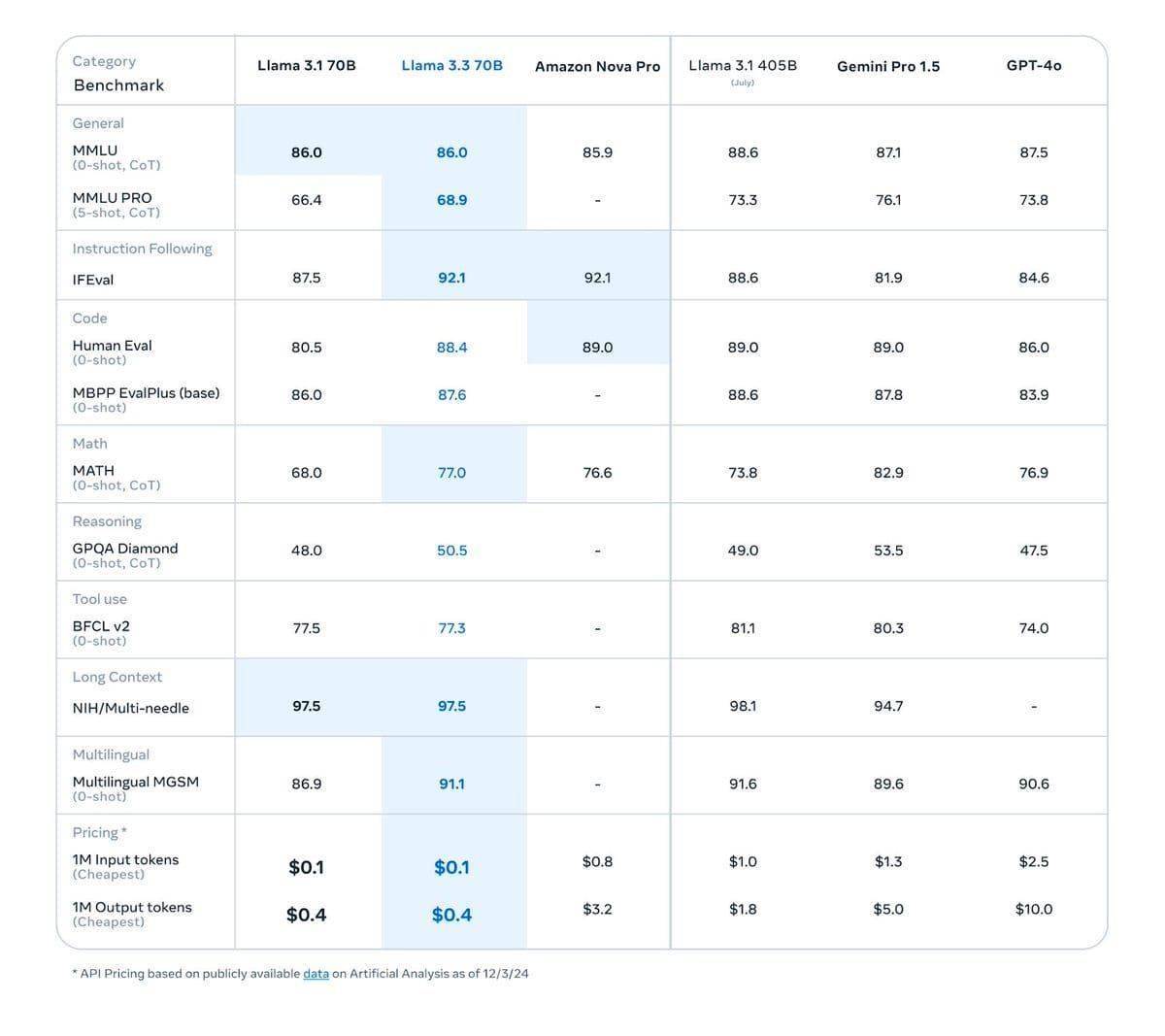
meta近期在人工智能领域再次发力,推出了其年度重量级大模型——Llama 3.3。这款新模型在参数规模上虽然只有700亿,但在性能表现上却能媲美参数高达4050亿的Llama 3.1版本,展现了极高的效率。
meta公司特别强调,Llama 3.3不仅在性能上有所提升,更重要的是其成本效益显著。这款模型能够在标准工作站上顺利运行,极大地降低了运营成本,同时依然能够为用户提供高质量的文本AI解决方案。这对于那些希望在AI领域有所作为但又面临资金压力的企业和个人来说,无疑是一个巨大的福音。
在功能方面,Llama 3.3也进行了全面优化。它支持多达8种语言,包括英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语,满足了全球不同地区用户的多样化需求。这一改进使得Llama 3.3在跨国企业和多语言环境下的应用中更具竞争力。
从架构上来看,Llama 3.3采用了优化的Transformer架构,并采用了自回归(auto-regressive)语言模型的设计。其微调版本更是结合了监督式微调(SFT)和基于人类反馈的强化学习(RLHF),使得模型在有用性和安全性方面更加符合人类的偏好。这一设计不仅提升了模型的性能,还增强了其在实际应用中的可靠性。
Llama 3.3还具备强大的上下文处理能力和多种工具使用格式支持。其上下文长度可达128K,能够处理更加复杂和丰富的文本信息。同时,它还支持与外部工具和服务集成,进一步扩展了模型的功能和应用场景。
在安全性方面,meta也采取了多项措施来降低模型滥用的风险。这包括数据过滤、模型微调和系统级安全防护等。同时,meta还鼓励开发者在部署Llama 3.3时采取必要的安全措施,如使用Llama Guard 3、Prompt Guard和Code Shield等工具,以确保模型的负责任使用。这些措施不仅保护了用户的隐私和数据安全,也提升了模型的社会责任感和可信度。






















